
AI Driven Design Shit Database

关注个人拉屎健康:
原始需求文档
git config user.name "oracle"
git config user.email "[email protected]"
以0到5天的间隔,生成数据,每一天的数据最多3条。
分析腹泻的时间(一天》=3次 或者2次的间隔少于60分钟)
拉屎困难的次数(3天拉一次)
拉屎时间,
拉屎顺畅程度
0 完全拉不出
1几乎拉不出来
2正常拉屎
3一泻千里
接口:散点图
每年拉屎报告
每周拉屎报告(4~7次算正常)
docker run -d --name clickhouse-server \
-p 8123:8123 \
-p 9000:9000 \
-v /Users/zeusro/data:/var/lib/clickhouse \
-e CLICKHOUSE_PASSWORD=123456 \
clickhouse/clickhouse-server:latest
准备底层数据
准备提示词,蒸馏回答
- mac 系统中创建备忘录,记录项目的背景信息
- 下载最新版 chatGPT 客户端,将备忘录作为背景信息,让AI创建数据库和表
- 改进提示词,微调数据表
- 将定制化需求作为新的提示词,让 chatGPT 导出相应sql
创建一个名为shit的数据库,用合适的字段描述场景
简化上述表格,去掉poop_times_today ,interval_minutes,notes,时间全部用 DateTime,用枚举表示 smoothness
周报和月报需要拓展一个需求, 将排便的频率和间隔做一个静态分析:如果一天拉大于等于3次,判定为腹泻;如果每周排便少于等于三次,判定为便秘,将这些定性作为周报,月报的结论体现出来
最终我们从ai的回答中提取关键信息
CREATE DATABASE IF NOT EXISTS shit
CREATE TABLE IF NOT EXISTS shit.toilet_log
(
id UInt64, -- 唯一ID
log_time DateTime, -- 拉屎时间,精确到秒
smoothness Enum8( -- 拉屎顺畅程度
'blocked' = 0, -- 完全拉不出
'hardly' = 1, -- 几乎拉不出
'normal' = 2, -- 正常拉屎
'diarrhea'= 3 -- 一泻千里
)
)
ENGINE = MergeTree
ORDER BY log_time;
INSERT INTO shit.toilet_log VALUES
(1, '2025-04-17 08:30:00', 'normal'),
(2, '2025-04-17 10:10:00', 'diarrhea'),
(3, '2025-04-18 09:00:00', 'blocked');
-- 查询一泻千里的次数:
SELECT count()
FROM shit.toilet_log
WHERE smoothness = 'diarrhea';
-- 查询每天拉屎次数:
SELECT toDate(log_time) AS date, count()
FROM shit.toilet_log
GROUP BY date
ORDER BY date;
-- 📊 腹泻日标记(先建个中间表/子查询)
SELECT
toDate(log_time) AS day,
count() AS poop_count,
(count() >= 3) AS is_diarrhea_day
FROM shit.toilet_log
GROUP BY day
ORDER BY day;
-- 📊 周报:腹泻、便秘、健康
WITH
-- 腹泻日统计
(SELECT
toDate(log_time) AS day,
count() AS poop_count
FROM shit.toilet_log
GROUP BY day) AS daily_stats
SELECT
toStartOfWeek(day) AS week_start,
count() AS total_days,
sum(poop_count) AS total_poop_count,
sum(poop_count >= 3) AS diarrhea_days,
(total_poop_count <= 3) AS is_constipation_week,
(diarrhea_days = 0 AND total_poop_count > 3) AS is_healthy_week
FROM daily_stats
GROUP BY week_start
ORDER BY week_start;
/*
is_constipation_week = 1 → 便秘周
is_healthy_week = 1 → 健康周
*/
-- 📊 月报:腹泻、便秘、健康
WITH
-- 腹泻日统计
(SELECT
toDate(log_time) AS day,
count() AS poop_count
FROM shit.toilet_log
GROUP BY day) AS daily_stats
SELECT
toStartOfMonth(day) AS month_start,
count() AS total_days,
sum(poop_count) AS total_poop_count,
sum(poop_count >= 3) AS diarrhea_days,
(total_poop_count <= 12) AS is_constipation_month,
(diarrhea_days = 0 AND total_poop_count > 12) AS is_healthy_month
FROM daily_stats
GROUP BY month_start
ORDER BY month_start;
/*
is_constipation_month = 1 → 便秘月
is_healthy_month = 1 → 健康月
*/
导入数据
根据这个表结构生成最起码400条测试数据,要求时间log_time,smoothness 随机分布。每一天产生的数据最少0条,最多3条.以csv形式导出。
日期到上下界调整一下,调整为 2024-01-01 ~ 2025-04-17
如何在mac系统中使用clickhouse client从本地文件csv中导入数据
brew install clickhouse
-- 隐私-安全性安全性 允许 clickhouse 命令执行
clickhouse client --host=localhost --port=9000 --user=default --password=123456 --query="INSERT INTO shit.toilet_log FORMAT CSV" < /Users/yourname/toilet_log_data.csv
之后我们打开 tabix 验证结果即可。
SELECT
count() AS all
FROM shit.toilet_log
设计应用层
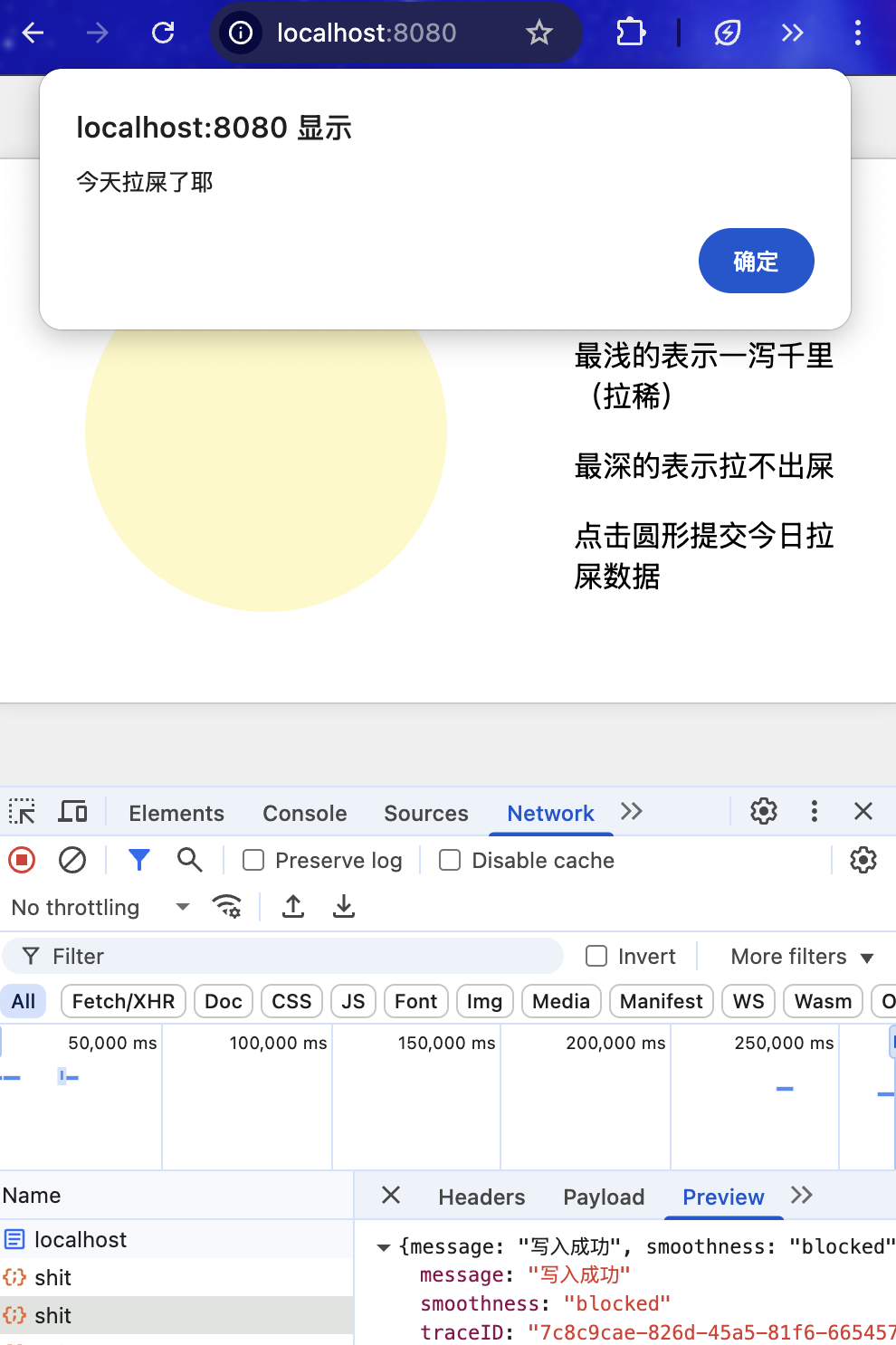
设计一个页面,中间是一个黄色的圆形,图片右边包含一个滚动条,滚动条往下滚动黄色会逐渐加深,一共有4种黄色。需要用原生html,不使用任何外部插件。
需要支持window,mac,ios,Android客户端。并且点击图片会触发post调用,参数是{"smoothness":1},smoothness是颜色深度,一共有1,2,3,4。4表示原色最深。
使用gin作为web框架,配置简单够用的功能(比如日志记录,traceid),并在里面加一个index.html页面,另外在后端中加一个路由“/shit”,指向Shit方法委托
shit方法实现对click house 数据库表shit.toilet_log 的写入
写一个docker-compose.yml,把这个gin的web项目,联通 click house 一起启动
微调一下内容结果,启动就行了。完整项目见shit
docker compose up --build
设计灵感
设计的灵感来自于我过往的经历。一位商人曾经说过,如果生活给了你一个柠檬,你应该把它榨成汁,然后喝下去。 那么化用这一种思维模式,如果有人在你的头上拉屎,你应该把他们记录下来,提取里面的关键性信息,找到一个适当的时机,再充分利用。
todo
可视化暂时用 tabix 分析了,也可以写几个接口,把上面的sql 拿来用,导出一个周报/月报,但我懒得搞了。
- 集成周报,月报图表,提供相应的数据和接口